An Efficient Lattice Algorithm for the Libor Market Model
and
Atomic Entanglement vs Photonic Visibility for Quantum Criticality of Hybrid System
One example comes from arXiv
and the other from viXra. For the
unfamiliar:
arXiv hosts nearly two million papers and is the standard, global repository for fields
such as Computer Science, Statistics, Quantitative Finance, Mathematics, and, in particular, Physics, the
discipline
for which it was originally established.
viXra hosts nearly forty thousand papers and was created as an alternative to arXiv for
"scientists who find they are unable to
submit their articles to arXiv.org because of Cornell University's policy of endorsements and moderation
designed to filter out e-prints that they consider inappropriate."
Question:Can you tell which title above came from an arXiv paper and which is from viXra?I guessed incorrectly for both of these titles, which can be found
here and
here.
The general task of determining the source of a given paper from, say, its title or abstract alone is non-trivial,
particularly
for those with little exposure to technical articles.
At garrettgoon.com/arxiv-vixra-quiz I have made a small quiz
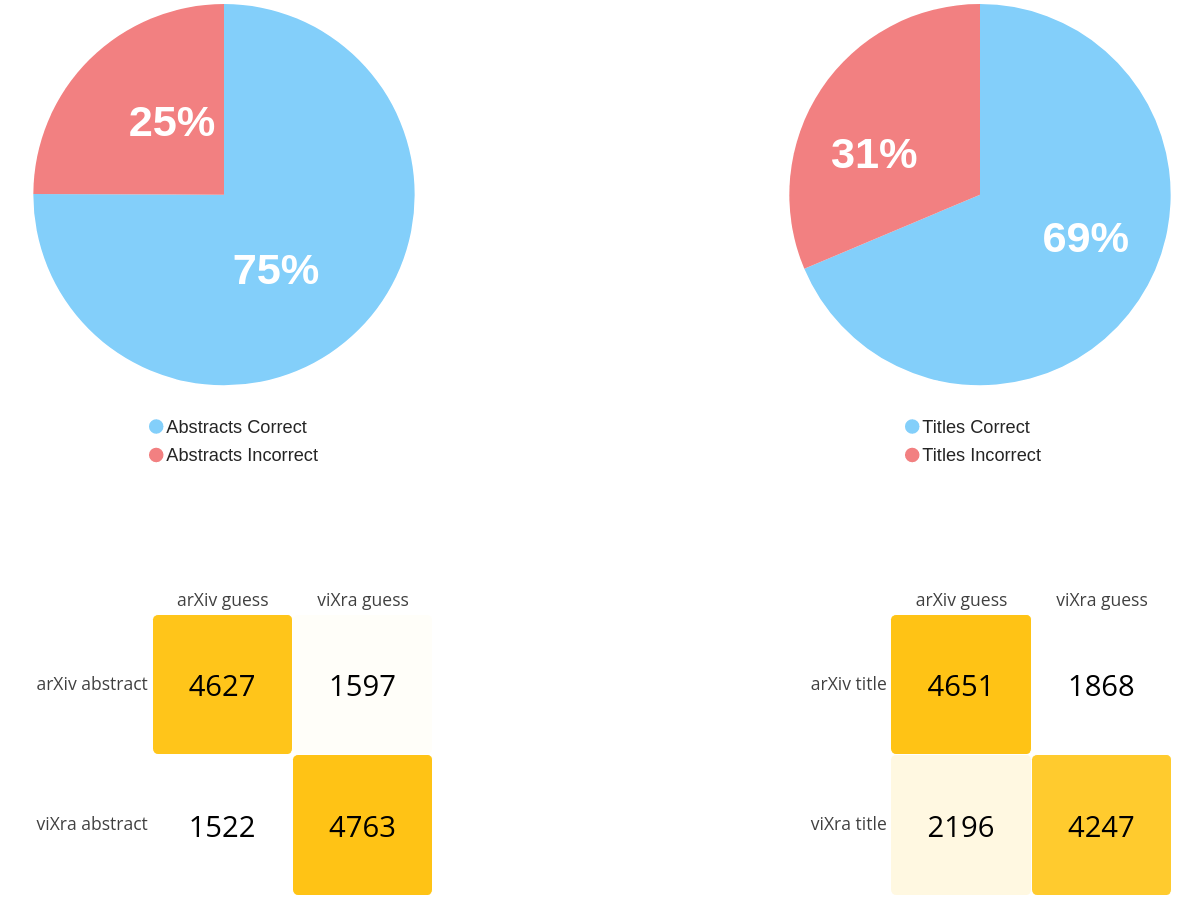
where you can test your own abilities. As of November 5, 2021 there have been over 25,000 total guesses
with the following results:
Participants are requested to self-identify as experts if they regularly read technical research articles.
These experts guessed correctly on \approx 78\% of the title questions and \approx 71\%
of the abstract questions. Non-experts guessed correctly on \approx 71\% and
\approx 66\% of these same tasks. Approximately three-fifths of all guesses came from experts.
Having seen the title alone, participants guess the correct source \approx 69\% of the
time.
Having seen the abstract alone, participants guess the correct source \approx 75\% of
the time.
A summarizing graphic can also be found above.
Machines
Though humans perform significantly better than random, there is room for improvement and surely one can
teach a computer to outperform the human baseline
arXiv itself uses Machine Learning models to assess its submissions. Published results include studies of plagiarism
detection and the correlation between submission time and citation accumulation.
Paul Ginsparg (arXiv founder)
gives fascinating talks on the subject..
This particular task of text classification is one of the classic problems
of Machine Learning (ML), falling under the subcategory of Natural Language Processing (NLP).
In the below series of posts I describe in detail the process of building increasingly sophisticated models for
this
classification task
In order to limit the scope of the project, most of the models focus on the (harder) problem of classifying
papers based on title alone.
. Along the way, I also attempt to explain various ML and Data Science
concepts in my own words with the hope that others may find the explanations informative. These often take the
form of
(long) footnotes
Here's an example: many common computations in ML are paralellized using broadcasting and
vectorized code. These are some of the most important practices to develop for efficiency.
Coming from physics, the tensor operations one performs in these calculations are also initially somewhat
bizarre looking (at least for me) and take some getting used to. Below I explain broadcasting in the way I would
have found helpful when initially learning about them.
Broadcasting involves operations between tensors of different sizes, where a tensor is an array-like object
T_{i_0 i_2\ldots i_N} with indices i_k\in\{0,
\ldots, d_{k}-1\} spanning different ranges, in general. In
pytorch, such a tensor is represented as an instance of the
torch.Tensor class, call it
t, which is said to be
(d_0, d_1, ...., d_N)-shaped. In
addition to the usual
matrix-multiplications and dot-products, in ML one often wants to do something like the following: take
(r, c)-shaped matrix and rescale all of the rows by the values contained in
an
(c, )-shaped vector. This is an uncommon operation in physics, where all
tensor manipulations tend to be invariant or co-variant under rotations (or other group transformations) of the
constituent tensors. An explicit, simple example with a matrix m
and
vector v:
m = \begin{pmatrix}
2 & 1 \\
0 & 2 \\
3 & 3
\end{pmatrix}\ , \quad v = \begin{pmatrix}
-1 \\
0 \\
4
\end{pmatrix}\quad \longrightarrow \quad m * v \equiv \begin{pmatrix}
-2 & -1 \\
0 & 0 \\
12 & 12
\end{pmatrix}\ ,
or in component form: m_{ij}, v_{k} \longrightarrow \left(m*v\right)_{ij} \equiv m_{ij}v_{j}.
Because the entries of the m*v tensor can all be computed independently from each other, the
calculation is amenable to parallelization and corresponding vectorized
pytorch code for the
above is simply the concise syntax below (using random entries instead of the preceding integers):
m = torch.randn(2, 3) # (2, 3)-shaped.
v = torch.randn(3) # (3, )-shaped.
mv = m * v # (2, 3)-shaped.
This type of broadcasting works with all of the usual infix operations
(*, /, +, -) and is possible for tensors T, U,
(t, u in code below) which satisfy the following criteria. Writing out the
indices, we take
T_{i_M\ldots i_{0}} to be (M+1)-dimensional and U_{j_N\ldots j_{0}}
to be (N+1)-dimensional with M \le N (without loss of generality), where the
ordering of the index subscripts is reversed from usual conventions for reasons that will
soon become apparent.
Writing out the sizes of these dimensions in code notation as
(t_M, ..., t_1, t_0) and
(u_N,..., u_1, u_0) for T and U,
respectively, T and U can be broadcast together if the sizes of each
of the
final M + 1 dimensions of both tensors (all of the ones they have in common)
are equal to one other or at least one of the dimensions is a trivial, singleton dimension of size one. That is
for each
k in
(M, ..., 1, 0), at least one of the following must be true:
A) t_k == u_k, so that the indices i_k and j_k
span the same range of values.
B) t_k == 1 or u_k == 1, so that at least one of i_k or
j_k
only takes on the value 0.
When the above holds, T and U can be broadcast into a new tensor V
which has N+1 indices V_{j_N\ldots j_{0}}, like the larger tensor
U, and is of shape
(u_N, ..., max(t_M, u_M), ..., max(t_0, u_0)). For instance:
t = torch.randn(5, 1, 3)
u = torch.randn(2, 1)
v = t + u # (5, 2, 3)-shaped
The components of V come from performing the infix operation between T
and U using the natural components of these latter tensors. That is, when T,
say, has an index which ranges over the same values as the corresponding index in V
, then the usual, non-trivial components of T are used. Otherwise, if the relevant
index in T is a trivial singleton index or is completely
missing (which is equivalent to inserting a dummy singleton index at the relevant location), the single value
of the tenor available at this index is used in the
computation for all values of the index in V. When a single value is used for multiple
components of V in this way, one says that it has been broadcast across a larger
dimension.
Analogous statements hold for U. In the
code example above, this works out as follows:
V_{ijk} is a three-dimensional, (5, 2, 3)-shaped tensor
whose components are
V_{ijk} = T_{i0k} + U_{j0}\ .
There is not really any other reasonable way that we could have combined T and U
into a
V-shaped object. In general, one can think about broadcasting as first taking T
and U, inserting dummy singleton indexes into the smaller tensor until the two are of
the same dimension (T_{i_M\ldots i_{0}}\longrightarrow T_{i_{N}\ldots i_{M+1}i_M\ldots i_{0}}
in the present case, i_k\in \{0\} for k > M), broadcasting all singleton
dimensions in both tensors as needed, and then finally performing the relevant infix operation between the
now-properly-sized tensors.
A final example of when this is useful and how to translate index notation to vectorized code. Imagine that
T_{ik} is an (n_t, d)-shaped tensor corresponding to
n_t different vectors (T's first index) which are each
d-dimensional (T's second index) and U_{jk}
is a similar (n_u, d)-shaped tensor.
If we wanted to get the
squared-distances between all such vectors, a (n_t, n_u)-shaped tensor
V_{ij}, we could write this in index form as
V_{ij} = \sum_{k}\left(T_{ik} - U_{jk}\right)^2 \ .
In the equivalent vectorized code computation, we first need to re-shape both tensors so that the
length-n_t component of
t and length-n_u component of
u lie along independent dimensions,
allowing them to be broadcast together into
the desired output shape. The requisite singleton dimensions can be inserted in
pytorch as in
t.unsqueeze(dim) to perform the insertion at dimension
dim or, alternatively, by slicing the
Tensor object with None inserted
in the appropriate location. Both methods are shown below. After this re-shaping, it is a simple matter of
taking differences, squaring, and summing appropriately. Very explicitly:
n_t, n_u, d = torch.randint(1, 100, (3,)) # Random dimensions.
t = torch.randn(n_t, d) # (n_t, d)shaped.
u = torch.randn(n_u, d) # (n_u, d)shaped.
t = t.unsqueeze(dim=1) # (n_t, 1, d)-shaped.
u = u[None, ...] # (1, n_u, d)-shaped.
t_u_diff = t - u # (n_t, n_u, d)-shaped.
t_u_diff_squared = t_u_diff ** 2 # (n_t, n_u, d)-shaped.
v = t_u_diff_squared.sum(dim=-1) # (n_t, n_u)-shaped.
to which more technical points are also relegated.
Project Posts
Links to all posts in this series.
Note: all code for this project can be found on my GitHub page.
Thank you to the Distill team
for making their
article template publicly
available. I also gratefully
acknowledge
useful conversations with Matt Gormley, Matt Malloy, Thomas Schaaf, and Rami Vanguri in the course of this
project.
Additional Links
This project is my first foray into Machine Learning and I have found the following links particularly helpful:
Jeremy Howard's Intro to
Machine Learning and Deep Learning
for Coders are great fun and much more focused on the practicalities of ML than the Stanford series
(the
two complement each other well).
Dive into Deep Learning is
useful as a quick reference for looking up details of various architectures.
Fluent Python for everything
python. A tremendous book.