Note:
The Jupyter/Colab notebooks relevant to this post are
here on my GitHub page.
My
Sequential Information
A central limitation of the baseline models considered previously
is that they have no means of efficiently using the information inherent to the ordering of the text. For
instance,
one would expect that the logistic regression and random forest models would perform just about as well
Recurrent Neural Networks (RNNs) are the basic architecture which attempts to capture the information in
the
relative ordering of inputs. I briefly review their properties below, some details of their implementation
in
RNNs, Briefly
General Structure
RNNs are relevant when our input data forms an ordered series
The inputs
In
The hidden states
A Specific Architecture: Gated Recurrent Units
I used Gated Recurrent
Units (GRUs) as the recurrent layers
-
Use
x_t and the preceding hidden stateh_{t-1} to determine what fraction (element-wise) ofh_{t-1} to hold onto and include in the updated stateh_{t} . The fraction $z_t$ is determined through the usual process of using weight-matrices (W ), bias-vectors (b ), and a sigmoid function\sigma(x) ,z_t \equiv \sigma\left(W_{iz} \cdot x_t +W_{hz}\cdot h_{t-1} +b_z\right)\ , such that the updated state will be of the formh_t= z_t * h_{t-1}+\ldots -
Use
x_t and the preceding hidden stateh_{t-1} to determine what new information fromx_t to include in the updated stateh_{t} . This new datan_t is determined through a similar process of using weights, biases, and non-linearities, applied pointwise:n_t \equiv \tanh\left(W_{in}\cdot x_t + b_{in} +r_t * \left(W_{hn}\cdot h_{t-1}+b_{hn}\right)\right) wherer_t is defined similarly toz_t r_t \equiv \sigma\left(W_{ir} \cdot x_t +W_{hr}\cdot h_{t-1} +b_r\right)\ . -
The fully updated hidden state is a weighted sum
This weighted-sum update step between of the previous hidden stateh_t andh_{t-1} is one of the central advantages of GRUs (and LSTMs) over the vanilla RNN architecture in which the update step is instead of the formh_t = \tanh\left(W_{ih}\cdot x_t +W_{hh}\cdot h_{t-1} + b_h\right) . To see one reason why, consider the limit in which the data has provided a very strong signal at some time-stept with all later data points being relatively uninformative. In this case, the architecture would perform best by holding onto the information in the current hidden stateh_t , using its parameters to maintainh_{t'} \approx h_t for allt'\ge t . The GRU could accomplish this relatively easily by ensuring the pre-activations (arguments of\sigma ) of the so-called update gatez_t are large and positive, such thatz_t\approx {\bf 1} is nearly the identity and thereby propagating forward the current hidden state relatively unscathed:h_{t}\approx h_{t-1} . Accomplishing the same means in the vanilla RNN is much more difficult, as one would need to choose the weights and biases such thath_{t} = \tanh\left(W_{ih}\cdot x_t +W_{hh}\cdot h_{t-1} + b_h\right)\approx h_{t-1} which is a far-tougher balancing act. In particular, even if one made the optimistic assumptions that the architecture could learn to push the weights and biases into the regime in which\tanh is approximately linear and the\sim W_{ih}, b_h terms contribute negligibly, such thath_t \approx W_{hh}\cdot h_{t-1} , then achieving the desired goal would still require carefully tuningW_{hh} so that it nearly acts onh_{t-1} as the identity. And even if this were accomplished so that hidden states at neighboring time-steps were approximately equal, states separated byn time-steps still diverge exponentially, scaling like the largest eigenvalue ofW_{hh} (\lambda_{\rm max} ) to then -th power:h_{t+n}\sim \lambda_{\rm max}^n h_t . This type of scaling is a general problem for RNNs, regardless of whether they are attempting to hold onto the current hidden state, known as the vanishing and exploding gradient problem. The weighted-sum update step of the GRU helps ameliorate this issue, though it does not resolve it entirely.h_{t-1} and the new informationn_t :h_t = (1 - z_t)* n_t + z_t * h_{t-1}
The weights
Bells and Whistles: More Layers and Directions
Finally, one could increase the depth of the RNN architecture by stacking multiple such
layers and could also process the inputs
Both features are essentially what they sound like, though the details are important.
-
Stacking
M RNNs leads to multiple hidden states:h_t \longrightarrow h_t^i ,i \in\{0, \ldots, N-1\} , one per layer. While thex_t are still the inputs for the firsti=0 layer, subsequent layers withi>0 process the hidden state of the preceding layer (h^{i-1}_t ) as their input. The outputs of the stacked RNN are the hidden states of the final layer across all time-steps:h^{N-1}_t . -
Bidirectional RNNs process the inputs forwards and backwards, with independent weights and biases used for each
pass. This is desirable in contexts such as arXiv/viXra classification, since the passes in the two directions
capture different contextual information. In
pytorch , the outputs of a bidirectional architecture come from concatenating the hidden states of the two passes togetherI found the concatenation step a little under-documented. The .output tensor is(batch_size, seq_len, 2 * hidden_size) -shaped, but it is not clear from the documentation what the entry at time-stept (output[:, t] ) corresponds to, precisely. Presumably (and correctly), the first half of the output (output[:, t, :hidden_size] ) is the hidden state generated after stepping through the firstt inputs (x[:, :t] ) in the forward direction. But do the entriesoutput[:, t, hidden_size:] corresponding the backwards direction arise from stepping backwards through the finalt entries of the input or through all entries from the end of the sequence all the way back to entryt ?x[:, -t:] orx[:, t:] ?
The answer is the latter:output[:, t] contains information from processing the firstt input entries in the forwards direction and the finalseq_len - t entries in the backwards direction. One can ask similar questions regarding thehidden tensor returned by the RNN and, thankfully, these are what one would expect: they are the final hidden states which arise from a forward pass and a backward pass, concatenated into a(2, seq_len, hidden_size) -shaped tensor. These statements can be verified (following this nice post) by creating a bidirectional RNN, two single-direction RNNs which have their weights tied to the bidirectional one, and comparing theoutput andhidden tensors of each as they run through a sequence in the relevant direction(s):# Create three simple GRUs, one of which is bi-directional. forward_gru = nn.GRU(input_size=1, hidden_size=1, batch_first=True) backward_gru = nn.GRU(input_size=1, hidden_size=1, batch_first=True) bi_gru = nn.GRU(input_size=1, hidden_size=1, batch_first=True, bidirectional=True) # Tie their weights together. for name, p in forward_gru.named_parameters(): getattr(forward_gru, name).data = getattr(bi_gru, name).data getattr(backward_gru, name).data = getattr(bi_gru, name + '_reverse').data # Pass inputs and reversed inputs as relevant into the RNNs. rand_input = torch.randn(1, 3, 1) rand_input_flip = rand_input.flip(1) forward_gru_output, forward_gru_hidden = forward_gru(rand_input) backward_gru_output, backward_gru_hidden = backward_gru(rand_input_flip) backward_gru_output_flip = backward_gru_output.flip(1) bi_gru_output, bi_gru_hidden = bi_gru(rand_input) # The below vanishes. forward_backward_output = torch.cat((forward_gru_output, backward_gru_output_flip), dim=-1) output_difference = forward_backward_output - bi_gru_output torch.testing.assert_close(output_difference, torch.zeros_like(output_difference)) forward_backward_hidden = torch.cat((forward_gru_hidden, backward_gru_hidden), dim=0) hidden_difference = forward_backward_hidden - bi_gru_hidden torch.testing.assert_close(hidden_difference, torch.zeros_like(hidden_difference))
Importantly, this means that if we wanted to use the hidden states which contain information from having seen the entire sequence in both directions, we would need to extractoutput[:, -1, :hidden_size] andoutput[:, 0, hidden_size:] , not simply the final entryoutput[:, -1] .
RNNs for arXiv/viXra
Sticking to the theme of starting simple, I analyze the performance of single-layer, uni-directional GRUs on
arXiv/viXra title data
Character- or Word-Level?
One needs to decide how exactly to encode the text as a series of tensors
-
One-Hot Encode: The simplest option is to let each time-step correspond to a single character and
represent each such character as a vector pointing in some cardinal direction
That is, if we index each of the possible .C , say, characters by an integerc \in \{0, \ldots, C-1\} , then denoting the character appearing at time-stept byc_t , one-hot-encoding corresponds to takingx_t^i = \delta^i_{c_t} withi the vector index. Thex_t are then(batch_size, seq_len, C) -shaped.pytorch has a built-inF.one_hot method for one-hot encoding text given anchars tensor holding character indices, but it's a nice exercise in using vectorized code to figure out how one would perform the encoding manually.
Whenchars is a simple one-dimensional,(seq_len, ) -shaped vector such thatchars[t] corresponds to the character index at thet -th position in the text, then the associatedone_hot tensor of shape(seq_len, C) can be generated by creating a zero-tensor of this same shape and then inserting ones at all appropriate locations, as in:# Use a random character sequence. chars = torch.randint(C, (seq_len, )) one_hot = torch.zeros(*chars.shape, C) one_hot[torch.arange(*chars.shape), chars] = 1.
Whenchars instead has a batch dimension and is of shape(batch_size, seq_len) , such thatchars[b, t] corresponds to the character index at thet -th position in the text in theb -th document in the batch, one can instead use the.scatter_ method to insert ones into the appropriately shaped zero tensor in a vectorized manner:# Use a random character sequence. chars = torch.randint(C, (batch_size, seq_len)) one_hot = torch.zeros(*chars.shape, C) one_hot.scatter_(dim=-1, index=chars.unsqueeze(-1), src=torch.ones_like(one_hot)) which is essentially whatF.one_hot is doing under the hood. -
Embeddings: Alternatively, one could let each time-step correspond to a single word
Or other series of characters separated from others by white space, per the details of text-normalization. We will refer to them all as "words", for simplicity. in the text. There are commonlyV\sim \mathcal{O}(10 ^5) or more unique words in a corpus' vocabulary, as opposed toC\sim \mathcal{O}(10 ^2) characters, making a one-hot encoding infeasible. Instead, we can assign each word to a vector living in someembedding_dim \ll V -sized vector space, with the components of each vector randomly initialized. The vector components are learnable parameters which mutate upon training.
I use both options. For embeddings, there are various choices to make. One has to choose both the dimension of
the embedding space

Architecture Details
The recurrent models are all fairly simple: the GRU consumes the one-hot-encoded or embedded text as inputs and
the ensuing hidden states (which are optionally first passed through a dropout layer) are fed into a
single fully-connected layer to predict a single number, the
probability that a given title comes from a viXra paper. I use
The
An important choice is precisely what data from the GRU hidden states is passed to the feed-forward layers. While
we could pass in only the hidden state from the final time step, since that is the unique state which has seen the
entire title text, this choice poses the risk of missing out on important information that may have appeared early
on in the title but which has faded out of the hidden state with time. So, instead of passing in this final
time-step (
The
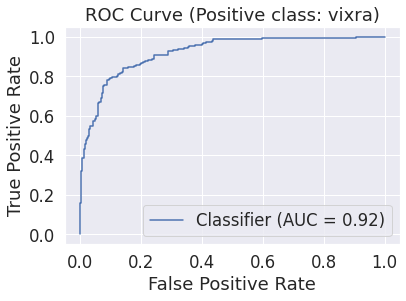
Performance and Interpretation
Validation Set
The one-hot and embedding-space recurrent architectures both achieved
Denoting the abstract score assigned to an example by
Interpretation
The simplicity of the present models allows us to see a glimpse of what is going on, though it is hard to draw any
very precise conclusions. In particular, the single number that our model predicts (the probability that a
given title is from a viXra paper) arises from a dot-product between the final dimension of the relevant
components of the GRU
This means that by re-scaling the GRU hidden states by the appropriate weights and biases, we can get a direct
view of the logits

Though the evolution in the model's prediction can be clearly seen in each case, it's difficult to interpret what any individual neuron is looking for (nor should such human-interpretable behavior be expected). There are some intriguing signs, but most seem to fall apart under scrutiny. For instance, the bright streak in the top image could plausibly be attuned to title length as its viXra signal grows as it sees more and more padding and terminates in a moderate viXra-leaning signal for this very short title. However, these same neurons terminate in a slightly arXiv-leaning signal for the similarly-short middle example and in the final image the neuron whiplashes back and forth upon encountering text and terminates in a moderate viXra signal for this much-longer title. Inconclusive.
My Papers
Finally, I examine the architecture's performance on my own papers. These models performed much better than the baselines when predicting the source of my own papers, thankfully, classifying 17- and 18-out-of-20 correctly for the word-embedding and one-hot models, respectively. See the figures below.


There is no longer an obvious correlation between title-length and viXra-probability, as there was for the baseline model predictions.